环境准备
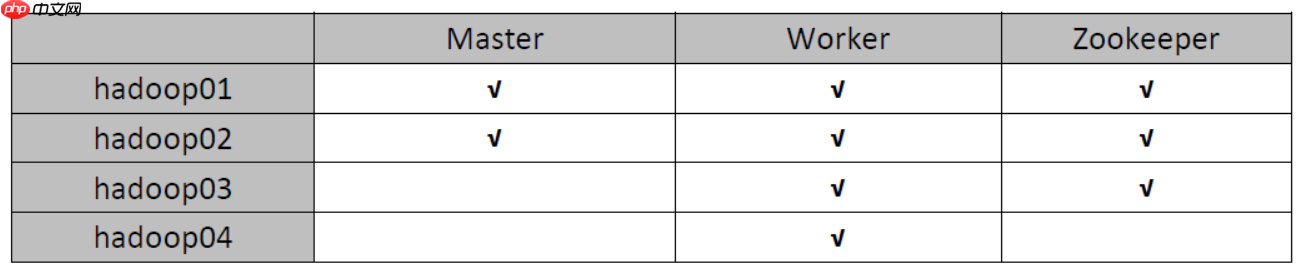
我使用的是CentOS-6.6版本的4个虚拟机,主机名为hadoop01、hadoop02、hadoop03、hadoop04。集群将由hadoop用户搭建(在生产环境中,root用户通常不可随意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。Zookeeper集群参考zookeeper-3.4.10的安装配置。spark安装包的下载地址为:https://www.php.cn/link/fee801ecfba08d39cd8ebed9fdcbe7e9。
- 集群规划
- 具体步骤
(1) 将安装包上传到hadoop01服务器并解压
(2) 修改spark-env.sh配置文件
(3) 修改slaves配置文件,添加Worker的主机列表
(4) 将SPARK_HOME/sbin下的start-all.sh和stop-all.sh这两个文件重命名,例如分别改为start-spark-all.sh和stop-spark-all.sh
原因:
如果集群中也配置了HADOOP_HOME,那么在HADOOP_HOME/sbin目录下也有start-all.sh和stop-all.sh这两个文件,当你执行这两个文件时,系统不知道是操作hadoop集群还是spark集群。修改后就不会冲突了。当然,不修改的话,你需要进入它们的sbin目录下执行这些文件,这肯定就不会发生冲突了。我们配置SPARK_HOME主要也是为了执行其他spark命令方便。
(5) 将spark安装包分发给其他节点
(6) 在集群所有节点中配置SPARK_HOME环境变量
(7) 启动Zookeeper集群
(8) 在hadoop01节点启动master进程
(9) 在hadoop02节点启动master进程
(10) 访问WEB页面查看哪个是ALIVE MASTER
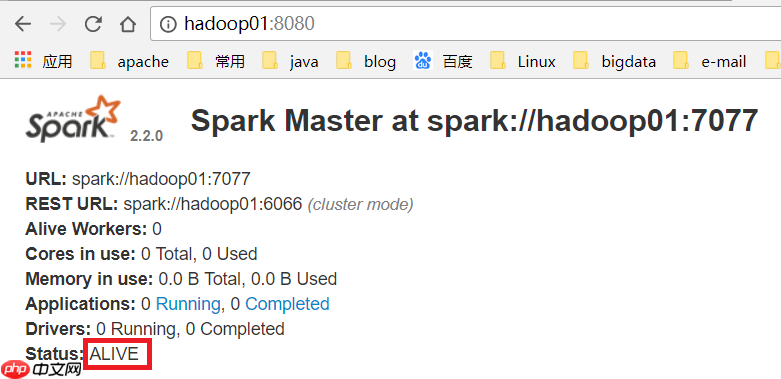
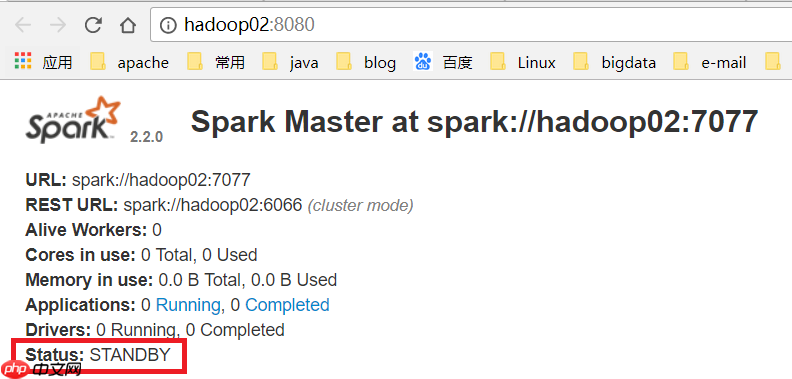
(11) 在ALIVE MASTER节点启动全部的Worker节点
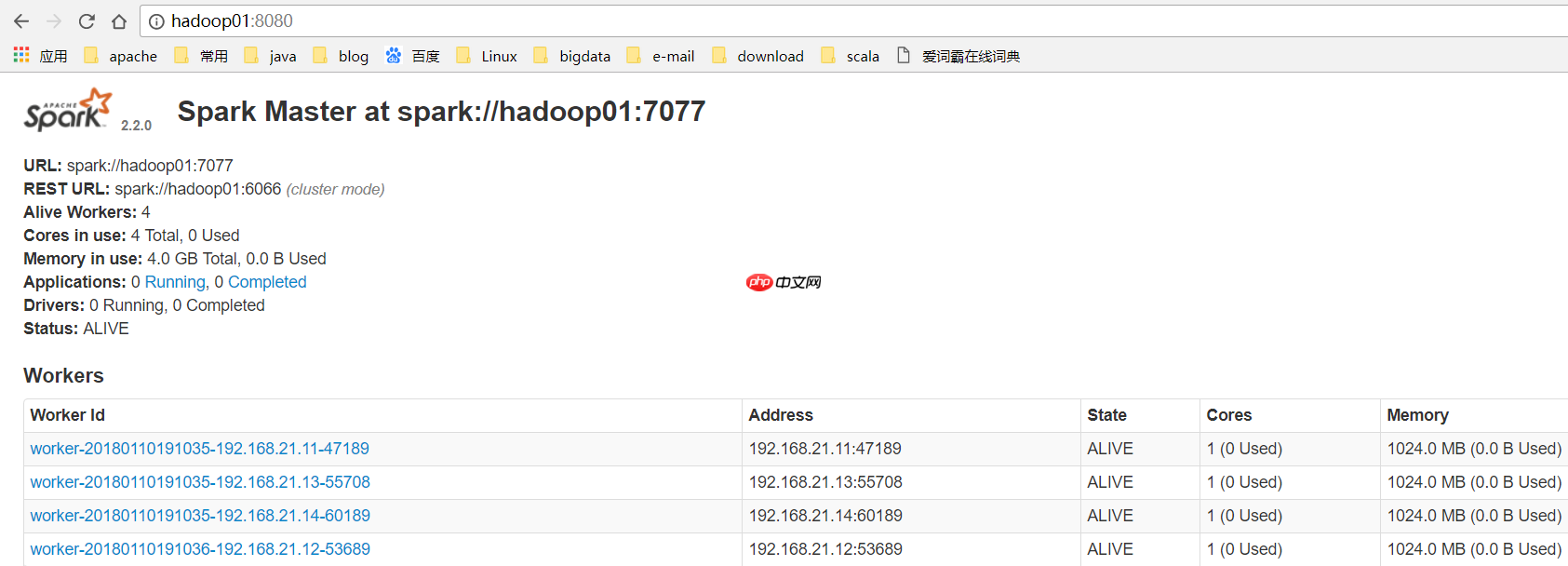
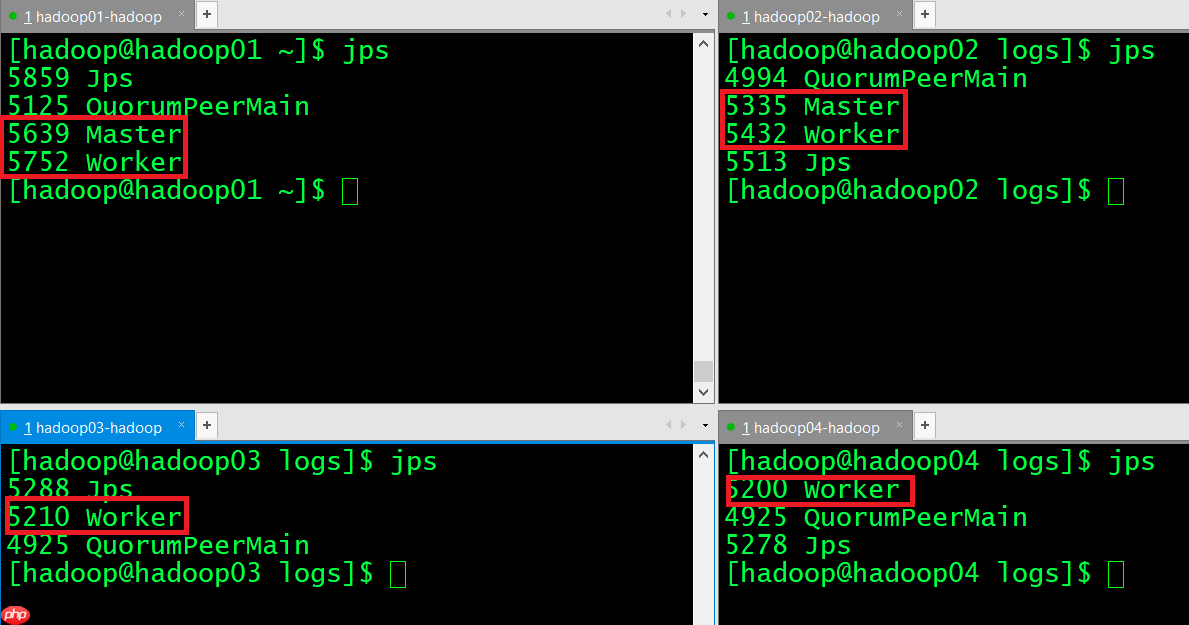
(12) 验证集群高可用正常的进程显示:
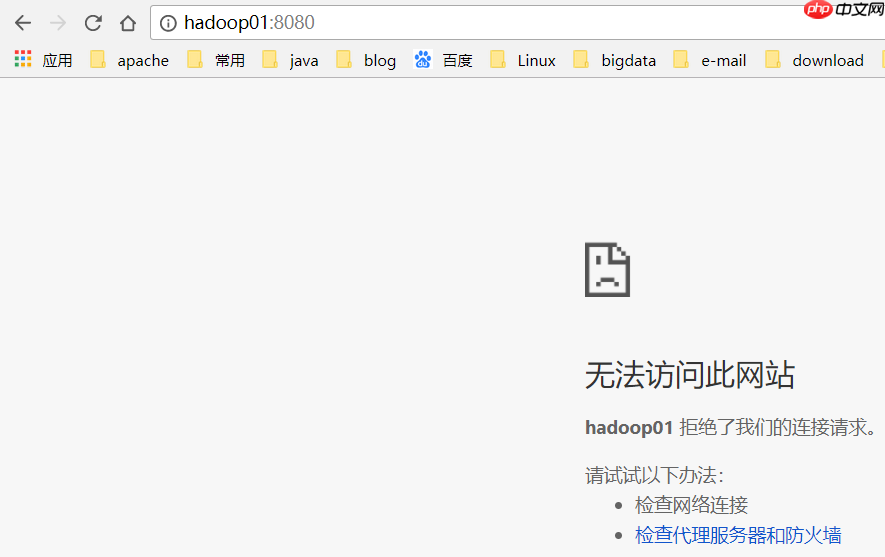
挂掉Active Master
hadoop01已经不能访问了:
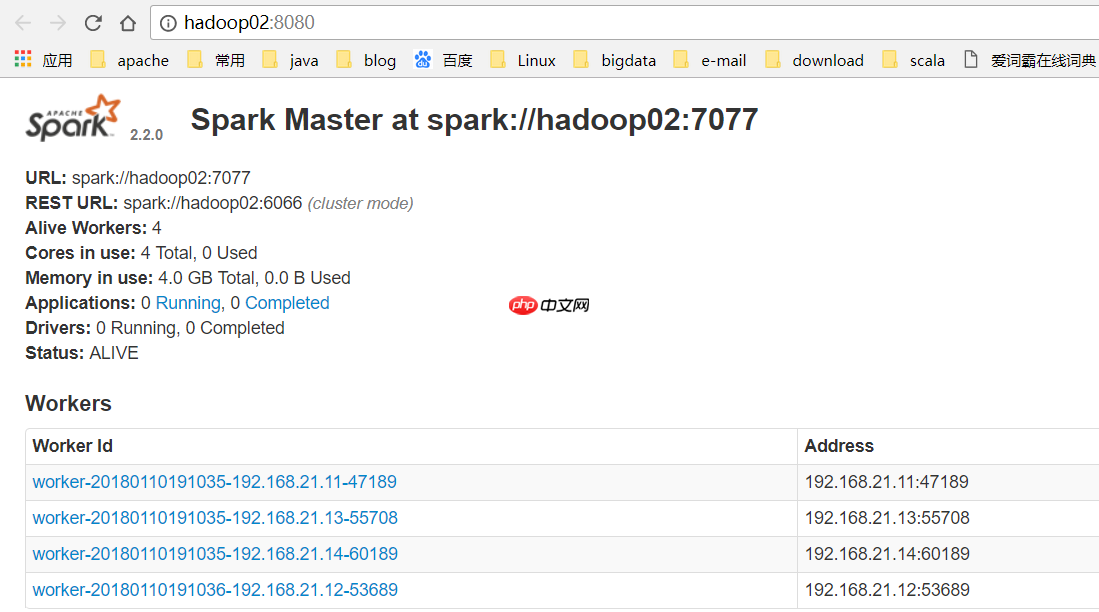
hadoop02变成了Active Master
启动hadoop01的master进程
hadoop01变成了Standby Master:
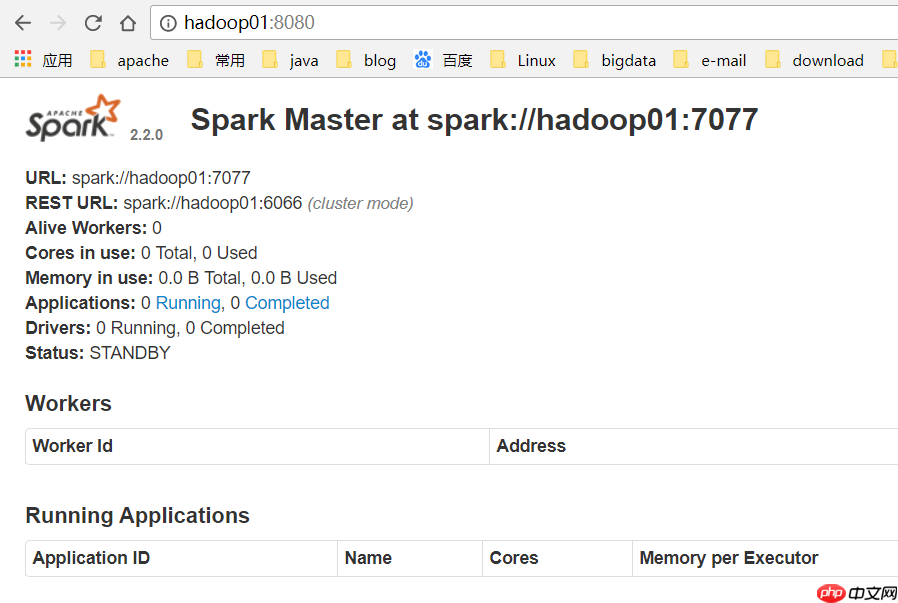
spark HA集群搭建成功!