在日常办公、财务分析、市场调研或学术研究中,我们经常会遇到一个令人头疼的问题:急需的数据被“锁”在pdf格式的文件里。pdf因其出色的跨平台稳定性和阅读体验而成为文档分发的首选,但其不可直接编辑的特性也成为了数据再利用的最大障碍。将pdf表格转换为可编辑、可计算的excel工作表,从而进行数据分析、图表制作或进一步处理,是一项至关重要的技能。
那么pdf怎么转换成excel表格呢?本文将深入探讨四种主流且高效的pdf转excel方法,涵盖从简单快捷的在线工具到精准强大的专业软件,乃至面向开发者的编程方案。每种方法都将配以详细的适用场景、 step-by-step 操作步骤和关键注意点,助您根据自身需求选择最佳解决方案,彻底摆脱手动录入数据的低效泥潭。
方法一:手动复制粘贴法——简单直接的应急之策
这是最基础、最无需学习成本的方法,适用于临时性、小批量的简单数据提取任务。
适用场景:
数据量极少:只有寥寥几行或几列数据。表格结构极其简单:没有合并单元格、嵌套表格等复杂结构。临时应急处理:没有网络、无法安装软件时的权宜之计。对格式要求极低:只需获取纯文本数据,不在乎任何格式。
操作步骤:
1、打开文件:使用Adobe Acrobat Reader DC或其他任何PDF阅读器打开您的PDF文件。
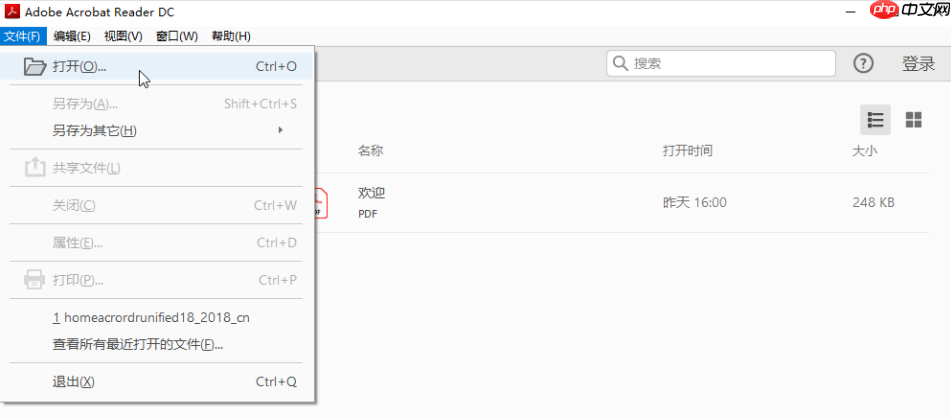
2、选择工具:点击工具栏上的“选择工具”(通常是一个光标箭头图标或“T”字图标)。
3、框选数据:在PDF页面上,用鼠标拖拽选中整个表格或您需要的部分数据区域。

4、复制数据:右键点击选中的区域,选择“复制”(或直接按
)。
5、粘贴到Excel:打开Microsoft Excel,选中一个空白单元格,右键点击并选择“粘贴”(或按
)。
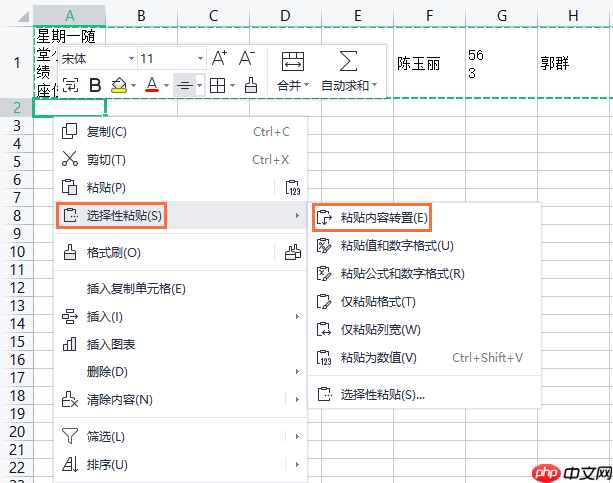
6、简单调整:检查数据是否被正确分列。有时所有数据会堆砌在同一列中。您可以使用Excel的“数据”选项卡下的“分列”功能,选择“分隔符号”(如空格或制表符)来将数据拆分到不同的列。
注意点:
格式丢失严重:所有字体、颜色、单元格边框等格式都会消失。分列错乱高发:这是该方法最大的痛点。如果原始PDF表格的列对齐不完美,复制后的数据极易出现串列、错位的情况,需要大量手动调整。无法处理图像:如果PDF中的表格是图片格式(如扫描件),此方法完全无效。效率极低:对于超过一页的表格,您需要重复操作无数次,耗时耗力,极易出错。结论:此方法仅推荐作为最后的手段,用于处理微不足道的数据任务。方法二:在线转换工具法——便捷高效的平衡之选
在线转换工具是绝大多数普通用户的首选。它们无需安装软件,通过浏览器即可完成转换,在便捷性和效果之间取得了良好平衡。
适用场景:
非敏感数据:处理不包含个人隐私、商业机密等敏感信息的文件。偶尔使用:转换需求不频繁,不想为偶尔一两次的任务购买付费软件。追求便捷性:希望快速解决问题,对安装软件感到麻烦。电脑性能有限:不想在本地电脑上运行大型OCR软件。
推荐工具:PHP中文网在线工具
操作步骤:
1、访问网站:在浏览器中打开PHP中文网的官方网站(https://pdftoword.55.la/)。
2、选择功能:在工具列表中找到并点击“PDF转Excel(https://pdftoword.55.la/pdf-to-excel/)”功能。
3、上传文件:点击“选择文件”按钮,从您的电脑上选取需要转换的PDF文件。您也可以直接将文件拖拽到网页指定区域。
4、等待处理:上传完成后,网站会自动开始处理文件。这个过程通常很快,对于包含复杂表格或需要OCR识别的文件,时间会稍长。
5、下载结果:处理完成后,页面会提示下载。点击“下载”按钮即可将转换好的Excel文件保存到本地。
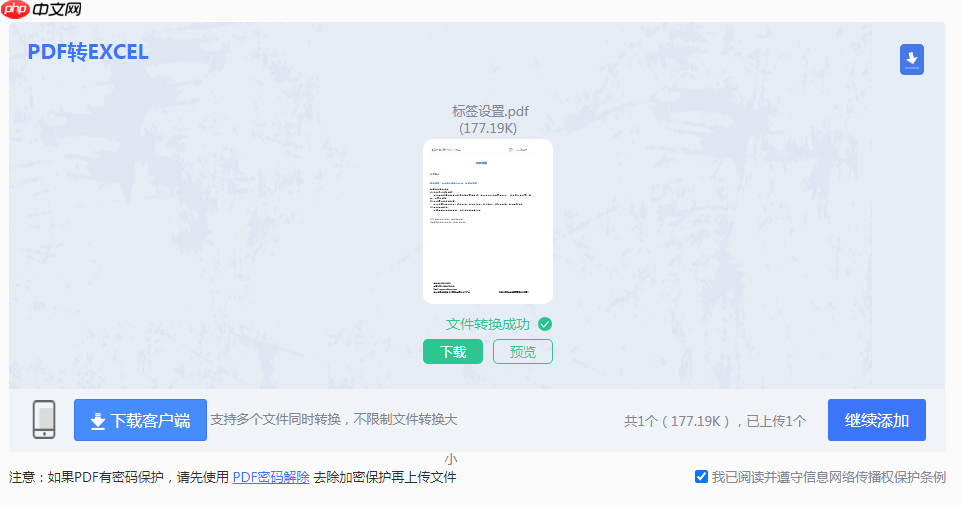
6、检查与校对:至关重要的一步! 立即在Excel中打开下载的文件,仔细检查数据是否有错位、遗漏或乱码,并与原PDF进行对比。
注意点:
数据安全与隐私:这是在线工具最大的风险。您需要将文件上传到第三方服务器,务必选择信誉良好、明确声明会定时删除用户文件的大平台(如Adobe)。切勿使用来历不明的小网站处理敏感数据。网络依赖:转换过程完全依赖于您的网络环境和服务器状态,网络不稳定时体验较差。功能限制:免费版本通常有诸多限制,如每小时/每天的可转换次数、文件大小上限(通常100MB以内)、转换速度慢、或带有水印等。频繁使用者可能需要购买付费套餐。转换效果参差不齐:不同工具的处理引擎不同,对复杂表格的解析能力有差异,可能需要尝试多个工具才能找到效果最好的一个。方法三:专业桌面软件法——精准强大的终极方案
对于需要频繁、批量处理复杂PDF表格,且对转换准确率和格式保真度有极高要求的用户,专业桌面软件是不二之选。
适用场景:
处理复杂表格:表格包含合并单元格、多页表格、嵌套表格、特殊符号等。批量处理:需要一次性转换几十上百个PDF文件。处理扫描件/图像PDF:文件是扫描得到的图片,必须依赖强大的OCR功能。数据敏感:文件涉及机密信息,必须在本地离线完成所有操作,杜绝网络传输风险。追求极致效果:需要高度还原原始表格的格式、公式甚至布局。
推荐软件: Adobe Acrobat Pro DC(行业黄金标准)、ABBYY FineReader PDF(OCR之王)、Wondershare PDFelement(性价比之选)。
操作步骤(以Adobe Acrobat Pro DC为例):
1、用Acrobat Pro打开PDF:确保使用的是付费的Acrobat Pro,而不是免费的Acrobat Reader DC。

2、选择导出工具:在右侧的“工具”面板中,点击“导出PDF”。如果未看到,可以点击顶部菜单栏的“文件” -> “导出到” -> “电子表格” ->
“Microsoft Excel工作簿”。
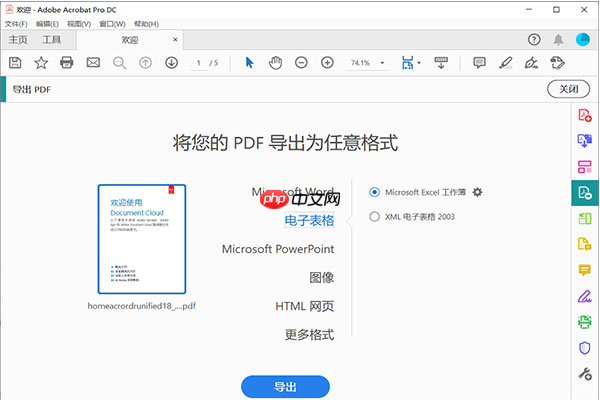
3、设置转换选项:点击“导出”按钮后,会弹出设置对话框。OCR识别:如果您的PDF是扫描件,软件会提示您使用OCR“识别文本”。您需要选择文档语言(如“中文(简体)”),以确保文字识别准确。
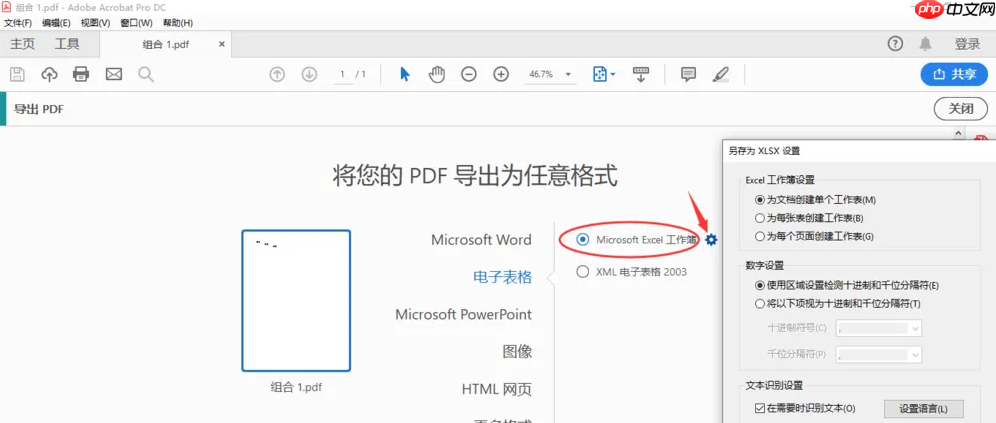
设置:您可以点击“设置”齿轮图标,进行更详细的配置,例如选择是导出“仅表单”还是“整个文件”,以及是否保留页面布局等。4、执行转换:点击“导出”按钮,选择保存位置和文件名,软件将开始在本地运行转换程序。
5、审核结果:转换完成后,仔细检查生成的Excel文件。Acrobat Pro的转换准确率非常高,尤其是对原生数字PDF,但对于极度混乱的扫描件,仍需人工复核。
注意点:
成本较高:专业软件如Adobe Acrobat Pro DC需要订阅,价格不菲。请评估您的使用频率是否值得这笔投资。系统资源占用:运行这些软件,尤其是在执行OCR时,会消耗较多的CPU和内存资源。学习曲线:虽然操作不复杂,但要完全掌握所有高级设置和批量处理功能,仍需花些时间学习。并非100%完美:即使是顶级软件,面对设计糟糕、布局奇特的表格时,也可能出现误判,人工校对仍是不可或缺的环节。方法四:编程与脚本法——面向开发者的自动化之道
对于程序员、数据分析师或IT管理员,通过编写脚本(如Python)来实现PDF到Excel的转换,可以实现最大程度的自动化和定制化。
适用场景:
集成到自动化流程:需要将转换任务嵌入到更大的数据自动化处理流水线中。大批量定期处理:每天/每周需要自动处理成千上万个PDF文件。高度定制化需求:需要精确控制提取哪些数据、如何清洗、以何种格式输出。服务器环境:在Linux服务器等无图形界面的环境中执行任务。
核心技术库(Python为例):
:专门用于从PDF中提取表格数据,底层是Java库,效果极佳。:另一个强大的表格提取库,能处理 lattice(有线)和 stream(无线)表格。 (fitz):一个更底层的PDF操作库,功能强大但使用更复杂。 或 :用于将提取的数据写入Excel文件。
简化操作步骤示例(使用Python + tabula-py):
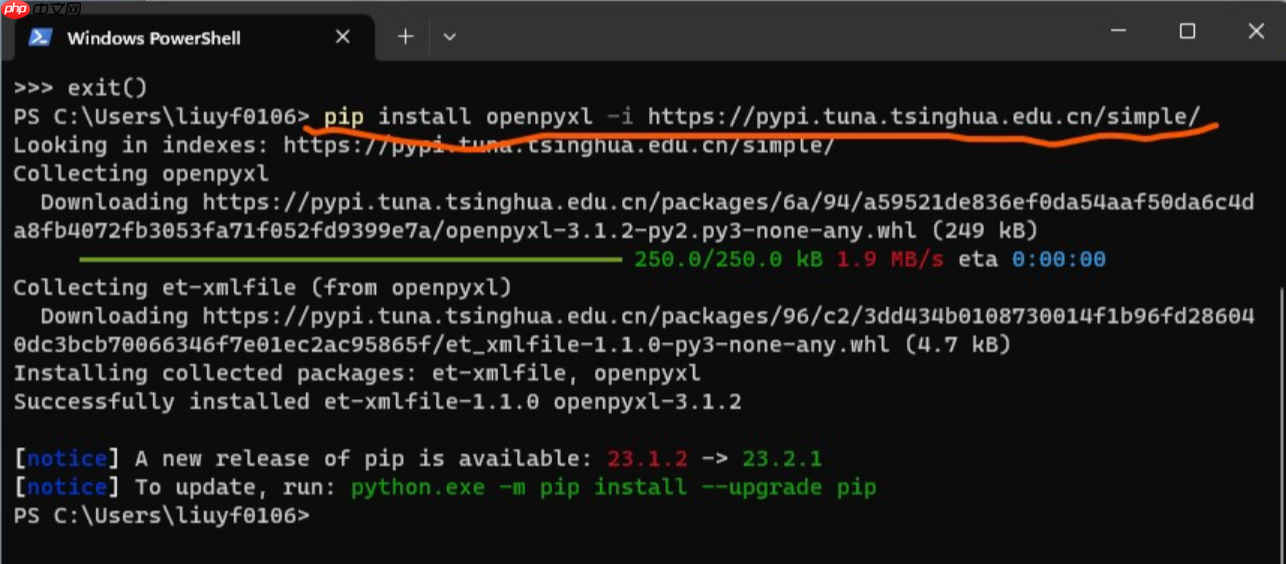
1、安装库:在命令行中运行
。
2、编写脚本:
3、运行脚本:在终端执行 。
4、检查输出:查看生成的
文件。
注意点:
技术要求高:使用者必须具备编程基础,尤其是Python和Pandas的基本知识。环境配置麻烦:需要安装Python解释器和相应的库,可能会遇到环境依赖问题(如Java)。调试复杂:对于布局特殊的表格,需要反复调整代码参数(如area、columns等)才能达到理想效果,调试过程可能很耗时。OCR支持有限: 等库主要处理原生文本PDF,对扫描件图片的支持需要结合其他OCR库(如),复杂度急剧上升。总结 方法 优点 缺点 最佳适用场景 手动复制无需任何工具和网络,立即可用效率极低,易出错,格式全无极少量、极简单数据的应急处理在线工具方便快捷,无需安装,跨平台有文件大小和次数限制处理非敏感、中小批量、非扫描件PDF专业软件精度高,功能强,支持OCR,可批量,离线安全成本高,占用资源,需安装频繁、大批量处理复杂/扫描件PDF,敏感数据编程脚本自动化,可定制,适合集成,处理海量数据技术门槛高,调试复杂程序员、数据分析师的大规模自动化任务
通用黄金法则: 无论选择哪种方法,转换后的数据校验都是最重要且不可省略的一步。软件和算法并非万能,特别是面对人类手工制作的、格式千奇百怪的表格时。花几分钟时间快速比对原PDF和生成的Excel,可以避免因数据错误导致的后续分析功亏一篑。