在elasticsearch中,无法直接添加新的分析器或修改已存在的字段映射,因此当需要变更配置时,必须创建一个新的、正确配置的索引,然后将原有数据迁移到新索引中,以确保新的映射和分析设置能够正确生效。
1、 操作别名的两种方法
2、 别名操作:单一执行
3、 支持将多个操作合并为原子性动作的别名机制
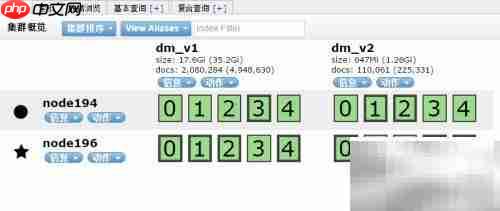
4、 设置别名
5、 {
6、 ]
7、 }
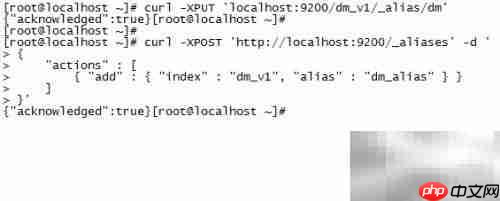
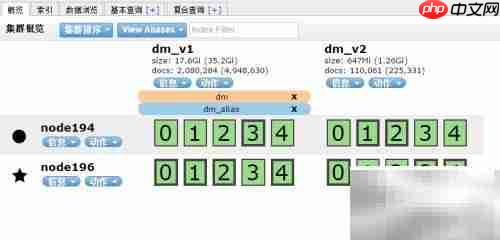
8、 删除别名
9、 {
10、 将索引 dm_v1 从别名 dm_alias 中移除,断开它们之间的关联,确保配置更新后生效,并在操作完成后验证结果是否准确。
11、 ]
12、 }

13、 在移除旧关联的同时将别名指向新索引,整个过程为原子操作,保证别名始终指向有效的索引。
14、 {
15、 ]
16、 }

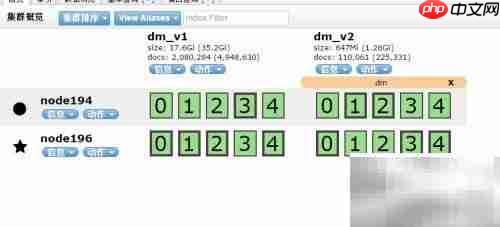
17、 查询别名信息
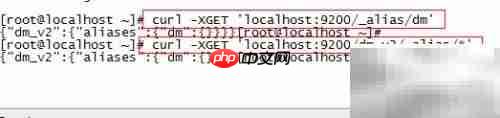
18、 根据别名查找其所关联的索引
19、 查看指定索引被哪些别名所指向
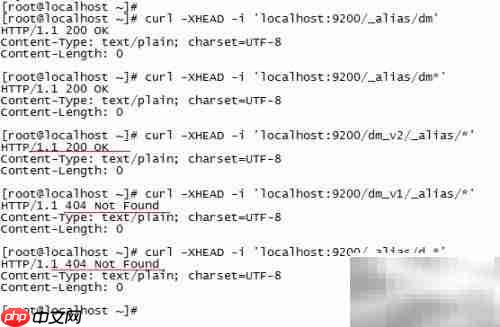
20、 可通过请求头部判断别名是否存在。
21、 别名相关问题已处理完毕,接下来进入数据迁移阶段。
22、 可参考此前关于Hadoop操作Elasticsearch的相关内容。
23、 使用 scan 和 scroll 实现数据的批量读取,配合 bulk API 进行批量写入,是一种高效的数据迁移方案。后续可根据实际需求优化具体实现细节。暂且告一段落!
24、 Hadoop与Elasticsearch之间的数据读写操作。