如果你的 erp/mes/crm/hr/oa 系统首页访问速度缓慢,尽管你确认在打开页面时没有大量的写入操作,那么或许是时候考虑使用缓存了。
一次实战:在 SQL Server 前加入 Redis 层
步骤:
-
在 Python 中启动 5000 个线程同时访问 SQL Server,执行存储过程,并记录每次请求的响应时间以及 Windows Server 的服务器状态;
-
安装 Redis,并将步骤 1 中需要的数据加载到 Redis 中;
-
在 Python 中启动 5000 个线程同时访问 Redis 取数,记录每次请求的响应时间以及 Windows Server 和 Redis 主机 CentOS 的服务器状态。
直接连接 SQL Server 时,5000 并发下的服务器状态:
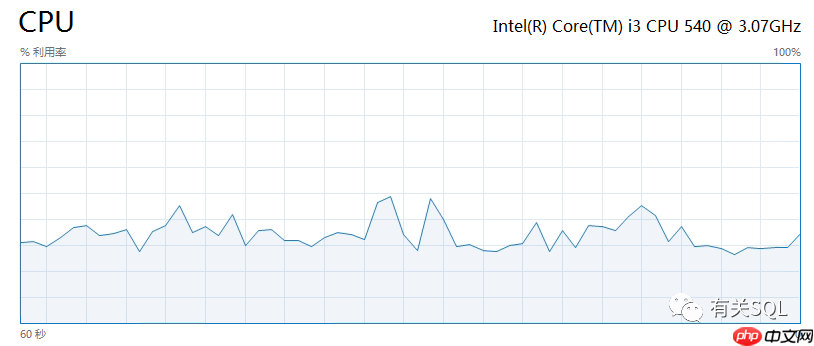 注意:一个方格子为 10%。这里大约维持在 30% 的 CPU 使用率
注意:一个方格子为 10%。这里大约维持在 30% 的 CPU 使用率
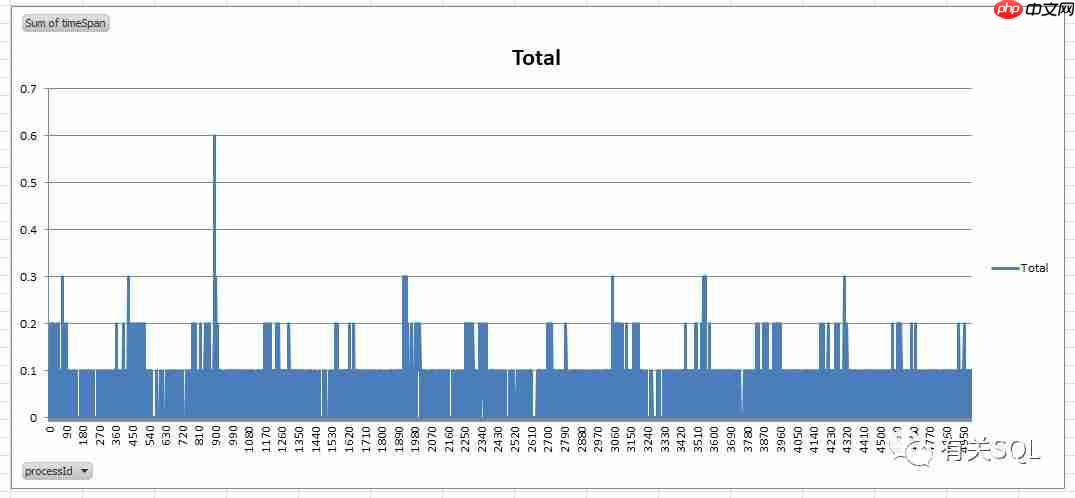
直接连接 SQL Server 时,5000 并发下的响应时间:
 直接连接 Redis 时,5000 并发下的服务器状态:
直接连接 Redis 时,5000 并发下的服务器状态:
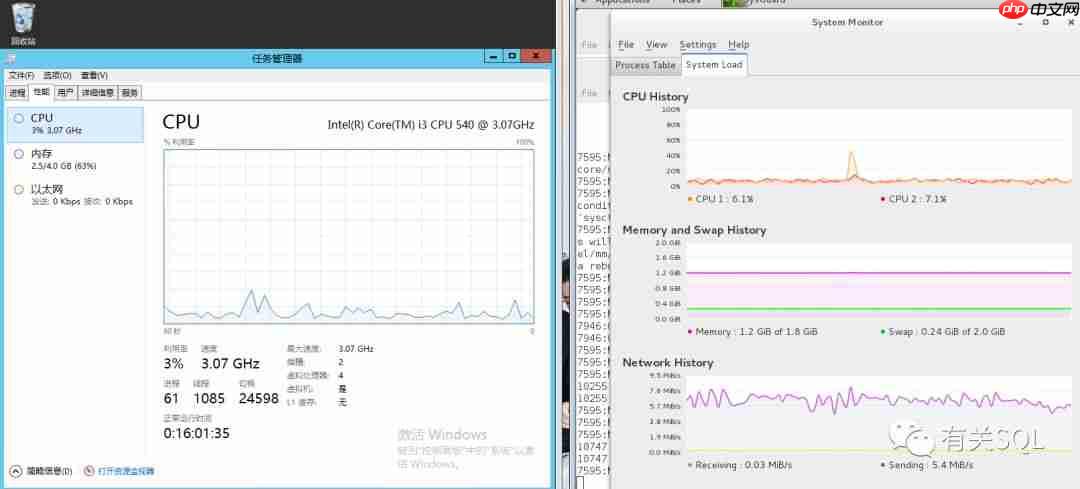 注意:Windows Server 的 CPU 使用率一直维持在不到 10% 的基准线上。而 CentOS 除了网络使用率高之外,CPU 和内存其实都稳定。
注意:Windows Server 的 CPU 使用率一直维持在不到 10% 的基准线上。而 CentOS 除了网络使用率高之外,CPU 和内存其实都稳定。
直接连接 Redis 时,5000 并发下的响应时间:
 相较之前直接连接 SQL Server,在响应时间上既没有优势也没有落后。
相较之前直接连接 SQL Server,在响应时间上既没有优势也没有落后。
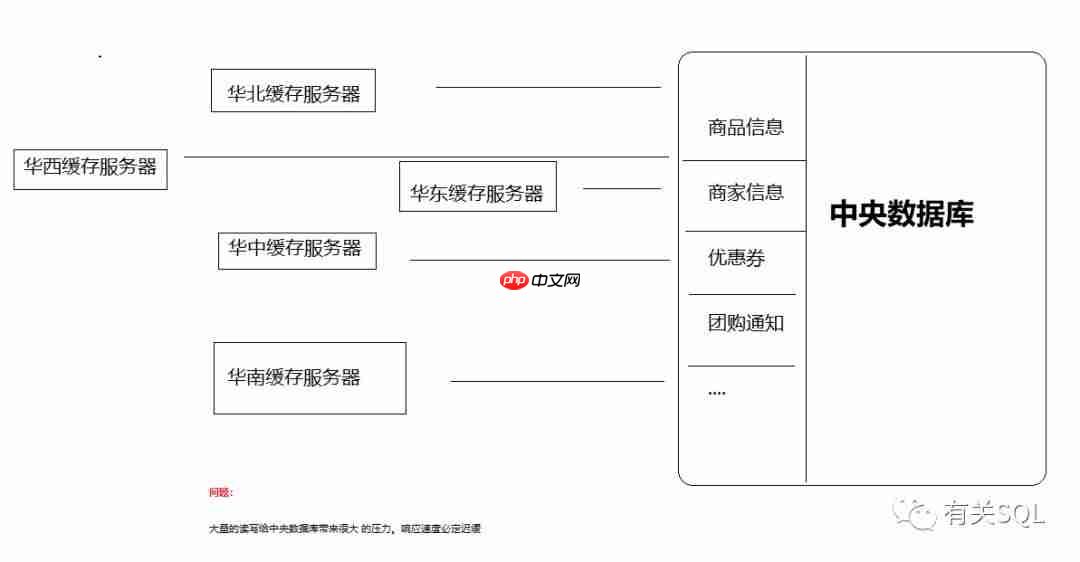
 缓存的本质在于区分 cache 和 buffer 非常重要!在电商系统中,所有商品加在一起将形成非常长的一份列表。购物页面被打开的瞬间,顾客肯定希望商品列表分门别类地展示在眼前,而不是延迟 2,3 秒才逐个展现出来。因此,在缓存服务器中,预先将数据库中百万甚至千万商品读取出来,然后分发给离顾客城市最近的二级缓存服务器上,便可给顾客一种快速从本地数据拉取商品列表的错觉。这一过程,可以称之为 cache。
缓存的本质在于区分 cache 和 buffer 非常重要!在电商系统中,所有商品加在一起将形成非常长的一份列表。购物页面被打开的瞬间,顾客肯定希望商品列表分门别类地展示在眼前,而不是延迟 2,3 秒才逐个展现出来。因此,在缓存服务器中,预先将数据库中百万甚至千万商品读取出来,然后分发给离顾客城市最近的二级缓存服务器上,便可给顾客一种快速从本地数据拉取商品列表的错觉。这一过程,可以称之为 cache。
顾客接着会挑选自己的商品下单。在挑选的过程中,先后会将挑好的商品存入缓存,这层缓存应当称为 Buffer,而这份 Buffer 通常称为购物车缓存。传统设计上将存入数据库的顾客购物列表,现在放到了 Redis 缓存中,大大减少了与数据库的交互,提高了速度。为什么不要直接与数据库交互的原因,顾客的购物车不一定最后会成单,有可能顾客只是收藏,也有可能最后一刻反悔不买了。
有效利用缓存 – 适用场景:写少读多 在大多数小规模应用中,采用一对一模式的缓存加数据库模式便足以满足系统反应速度。过多过早地采用复杂的缓存架构只能带来负担。很多数据写入缓存就失效,还没被请求访问。从适用角度来考虑,类似新浪微博大 V 的言论,做好缓存设计就显得十分有价值。写一次就有数千万次访问,这类缓存对系统来讲就有意义得多。
缓存适用场景 – 热点数据 在购物场景中,热点数据可以有:最受欢迎的商品,团购以及礼券等。而非热点数据可以是:订单历史,用户评论等。缓存通常是用内存资源做数据存储,而内存价格相比硬盘价格要贵很多,不分轻重把所有数据都放入内存,肯定加大硬件的成本。所以分清楚系统的热点数据是哪一块,再抽取这块数据到缓存服务器内存中这一策略,肯定是最佳的。稍稍要记一笔的是,如何判断热点数据,以及非热点数据如何做请退处理。