其实我也算是入门爬虫,目前也还有很多东西没有吃透,比如很多人入门选择使用的正则式我就没记清楚,对于很多反扒也并不算特别深入。但这并不影响我学习爬虫的信心和兴趣。。。没办法,必须要学啊。很多数据我不能跪着求别人给,因为别人不会给。。。被逼着学习爬虫,希望我的学习能有好结果吧
import json
import re
import requests
from requests import RequestException
url = “https://movie.douban.com/cinema/nowplaying/shanghai/”
###headers={‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36’}
response = requests.get(url,headers=headers)
html = response.text
pattern = re.compile(‘
.*?

items = re.findall(pattern, html)
for item in items:
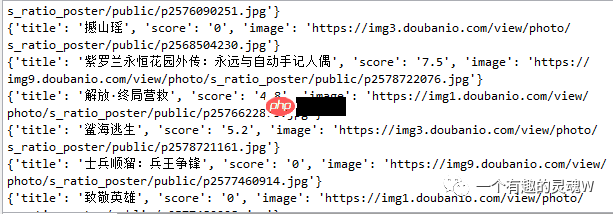
a={‘title’: item[0],’score’: item[1],’image’: item[2],}
print(a)
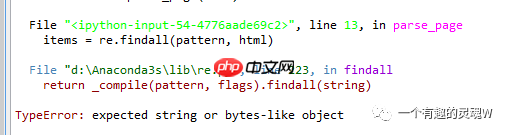
这样写要报错:
所以:
虽然例子简单,但是对于新手来说还有很多不友好的地方,我在学习的时候发现程序报错。
仔细检查代码之后发现:
requests.get(url)得到的结果是【418】,是被网站反扒了。需要加一个请求的头
headers={‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36’} —随便百度的,你可以用自己的电脑和浏览器
最后:
url = “https://movie.douban.com/cinema/nowplaying/shanghai/”
headers={‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36’}
response = requests.get(url,headers=headers)
html = response.text
pattern = re.compile(‘
.*?
items = re.findall(pattern, html)
for item in items:
a={‘title’: item[0],’score’: item[1],’image’: item[2],}
print(a)