OCR识文找图工具1.2 使用指南
工具概述
ocr识文找图工具1.2 是一款结合ocr技术的智能图像检索工具,能够通过图片中的文字内容进行搜索,并支持文件的复制、移动等管理操作。该工具支持便捷的拖拽功能,采用先进的 pp-ocrv5 识别算法,确保识别效率与准确率。
核心优势
(1)支持多线程并发处理,可批量导入任意数量的图片文件
(2)本地离线识别,不依赖网络或第三方API,数据安全有保障,识别速度由设备性能决定
(3)提供试用体验,用户可先测试功能,满意后再正式使用,不满意无需付费
界面功能分区说明
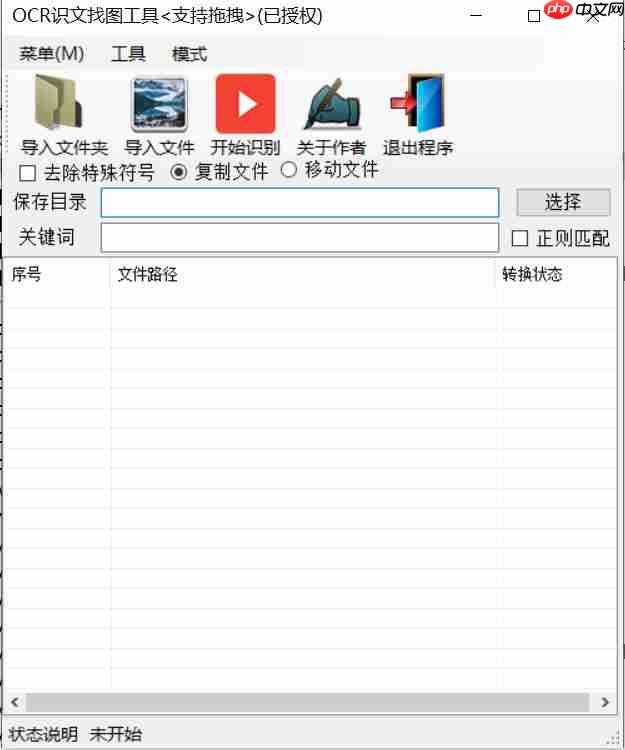
顶部菜单栏:包含“菜单(M)”、“工具”、“模式”三大主菜单
功能按钮区:
- 导入文件夹
- 导入文件
- 开始识别
- 关于作者
- 退出程序
选项设置区:
- 去除特殊符号
- 复制文件
- 移动文件
路径设置区:
- 保存目录选择
- 关键词输入框
- 正则匹配开关
文件列表区:显示文件序号、文件路径及转换状态
状态栏:实时显示当前操作进度与统计信息
详细操作流程
第一步:导入图片或文件夹
方式一:拖拽导入
将图片文件或整个文件夹直接拖入软件主窗口,系统将自动加载并解析文件内容。
方式二:按钮导入
点击“导入文件夹”按钮选择目标文件夹,或点击“导入文件”选择一个或多个图片文件进行导入。
第二步:配置搜索条件
关键词搜索:
在“关键词”输入框中输入需要查找的文字内容,系统将检索包含这些文字的图片。
正则匹配(高级功能):
勾选“正则匹配”选项后,可使用正则表达式实现更复杂的文本模式匹配,适用于专业用户。
第三步:设定输出参数
保存目录设置:
点击“选择”按钮指定结果文件的输出路径;若未设置,则默认在原目录下操作。
操作类型选择:
- 勾选“复制文件”:将符合条件的图片复制到目标目录
- 勾选“移动文件”:将匹配的图片移动至指定位置
- 若两项均不勾选,则仅显示搜索结果,不做文件操作
文本预处理:
启用“去除特殊符号”可自动清理OCR识别结果中的标点、符号等非必要字符
第四步:启动识别过程
确认所有设置无误后,点击“开始识别”按钮,系统将执行以下操作:
- 对每张图片进行OCR文字提取
- 根据关键词或正则表达式匹配目标内容
- 按照设定执行复制或移动操作
第五步:查看处理结果
文件列表区:
查看“转换状态”列,了解每张图片的识别与匹配情况,成功匹配的条目会有明显标识。
状态栏信息:
显示整体处理进度、已处理文件数、匹配成功数量等统计信息。
高级功能介绍
- 批量处理能力:支持一次性处理数百甚至上千个文件,高效省时
- 多关键词搜索:在关键词框中使用分号(;)分隔多个查询词,实现多条件筛选
- 结果导出功能:可通过菜单选项将搜索结果导出为文本或表格文件,便于后续分析
使用提示
- 图片中文字的清晰度直接影响OCR识别效果,建议使用高分辨率、无模糊的图像
- 处理大量文件前,建议先用少量样本测试识别效果
- 中文识别准确率较高,英文或特殊字体可能存在误差
- 复杂排版(如多栏、旋转文字)可能影响识别,必要时可预处理图片
常见问题解答
Q: 为什么某些图片无法识别出文字?
A: 请检查图片是否模糊、光线是否充足、文字方向是否正确,可尝试调整图片角度或增强对比度后重新识别。
Q: 如何提升识别准确率?
A: 推荐方法包括:使用清晰原图、输入更精准的关键词、必要时启用正则匹配,或对图片进行裁剪优化。
Q: 正则匹配如何使用?
A: 需掌握基本正则语法,例如
表示任意字符序列, 匹配数字, 表示以abc开头的文本等。
本使用指南基于 OCR识文找图工具1.2 版本编写,实际功能以软件最新版本为准。首次使用建议从小批量文件开始,熟悉操作流程后再进行大规模处理。