一、起源
在前一篇文章中,我分享了一个跨平台头文件的示例,该示例在 Windows 平台上更为重要,因为它需要处理库函数的导入和导出声明(dllexport、dllimport)。基于这个头文件,我们可以进一步扩展,以实现更细粒度的控制,比如对编译器和其版本的判断。
在源代码中,我们同样会遇到一些跨平台的问题。不同平台上的相同功能,实现方式可能有所不同。那么,如何有效地组织这些平台相关的代码呢?本文将探讨这个问题。
PS:文末将提供一个简单的跨平台构建代码示例。
二、问题引入
假设我们要编写一个库,需要实现一个获取系统时间戳的函数。作为库的作者,你决定提供以下API函数:
我们的任务是在函数实现中,通过不同平台下的C库或系统调用来计算系统当前的时间戳。
在Linux平台下,可以通过以下代码实现:
在Windows平台下,可以通过以下代码实现:
那么问题来了:如何将这两段平台相关的代码组织在一起?下面将介绍三种不同的组织方式,这些方式没有优劣之分,适合每个人和团队的不同习惯。
此外,这个示例中只有一个函数,而且较短。如果有许多跨平台的函数,且都很长,你的选择可能会有所不同。
三、三个解决方案
方案1
直接在接口函数中,通过平台宏定义来区分不同平台。
平台宏定义(T_LINUX, T_WINDOWS)是在前一篇文章中介绍的,通过操作系统和编译器来判断当前平台,并定义统一的平台宏供我们使用:
代码组织方式如下:
这种方式将所有平台代码放在API函数中,通过平台宏定义进行条件编译。由于代码较短,看起来还不错。
方案2
将不同平台的实现代码放在独立的文件中,然后通过#include预处理符号,在API函数中引入平台相关的代码。
增加两个文件:
(1) t_time_linux.c
(2) t_time_windows.c
(3) t_time.c
这个文件不做任何事情,仅用于include其他代码。
elif defined(T_WINDOWS)
else
endif
有些人可能不喜欢这种组织方式,因为通常我们会include头文件(.h),而这里通过平台宏定义include不同的源文件(.c),感觉有些怪异。
实际上,一些开源库也是这样做的,例如:
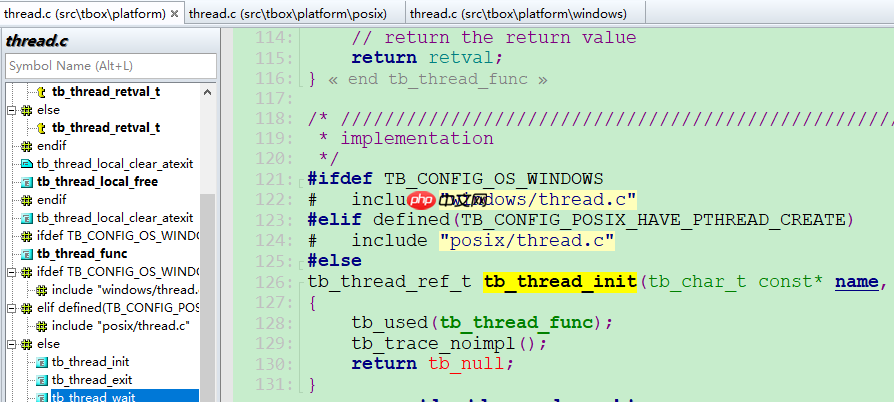
方案3
在方案2中,我们是在源代码中填入不同平台的实现代码。
实际上,我们可以换一种思路,既然已经根据平台的不同放在了不同的文件中,那么可以通过让不同的源文件加入到编译过程中来实现。
我们使用cmake工具来构建测试代码,因此可以编辑CMakelists.txt文件,来控制参与编译的源文件。
CMakelists.txt文件部分内容:
这种组织方式让代码看起来更“干净”。同样,我们也可以看到一些开源库也是这样做的:
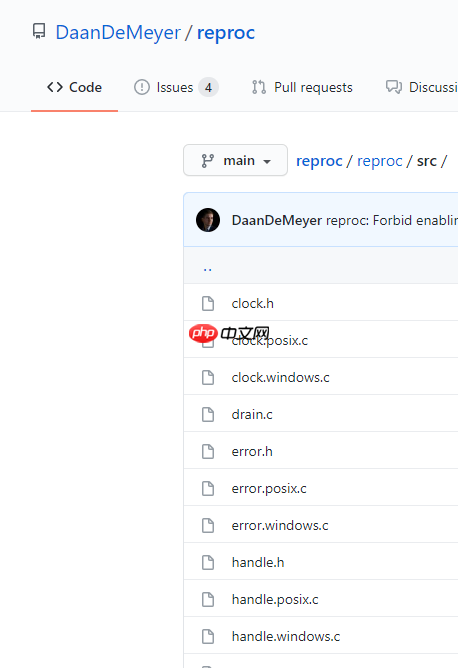

四、One More Thing
由于文章篇幅原因,上述仅展示了代码片段。
我编写了一个最简单的demo,使用cmake来构建跨平台的动态库、静态库和可执行程序。这个demo的主要目的是作为一个外壳,用于测试文章中的代码。
在Linux平台下,可以通过cmake指令手动编译;在Windows平台下,可以通过CLion集成开发环境直接编译和执行,也可以通过cmake工具直接生成VS2017/2019解决方案。
这个demo已上传至gitee仓库,有兴趣的小伙伴可以通过公众号dg36获取克隆地址。